

Project information
- Category: Generative AI, Diffusion Models, Text-to-Image, Deep Learning
- Project date: August, 2023
- GitHub: Text2Canvas
- Live Demo: HuggingFace Spaces
Introduction
Text2Canvas is an AI-powered service developed for MSML/DATA612 at the University of Maryland that employees deep learning methods to translate text prompts into sprite/pixel art. This project aims to replicate emerging text-to-image models by creating a lighter, less complex version focused specifically on sprite/pixel art generation.
The human brain relies heavily on visual feedback and responds better to visuals compared to text. Visual data is more informative, alluring, and reduces the chances of misunderstanding or false interpretation. Text2Canvas bridges the gap between written content and visual artistry, enabling users to transform their textual ideas into visual masterpieces.
Objective
The primary objective of Text2Canvas was to develop a text-to-image generator that seamlessly translates textual descriptions into visually captivating and accurate images. However, during our work, we faced significant resource constraints.
Our refined objectives were to:
- Create a model capable of generating sprite images based on feature vectors
- Specialize in generating sprite/pixel art from text descriptions
- Implement U-Net diffusion model architecture for sprite generation
- Develop a user-friendly interface for designers and developers
- Optimize the generation process for sprite-specific aesthetics
- Deploy the solution in a cloud environment for easy accessibility
Process
The development of Text2Canvas involved several key phases:
- Deep Learning Research: Studied diffusion models including T5 text encoders and U-Net architectures for image generation
- Dataset Acquisition: Integrated the Character Animation Dataset from v7labs.com, containing 672 sprites with 120,000 total images
- MinImagen Implementation: First attempted to create a minimal version of Google's Imagen model, which faced challenges with model stability and computational resources
- Sprite Generation Development: Pivoted to implementing a Denoising Diffusion Probabilistic Model (DDPM) specifically for sprite generation
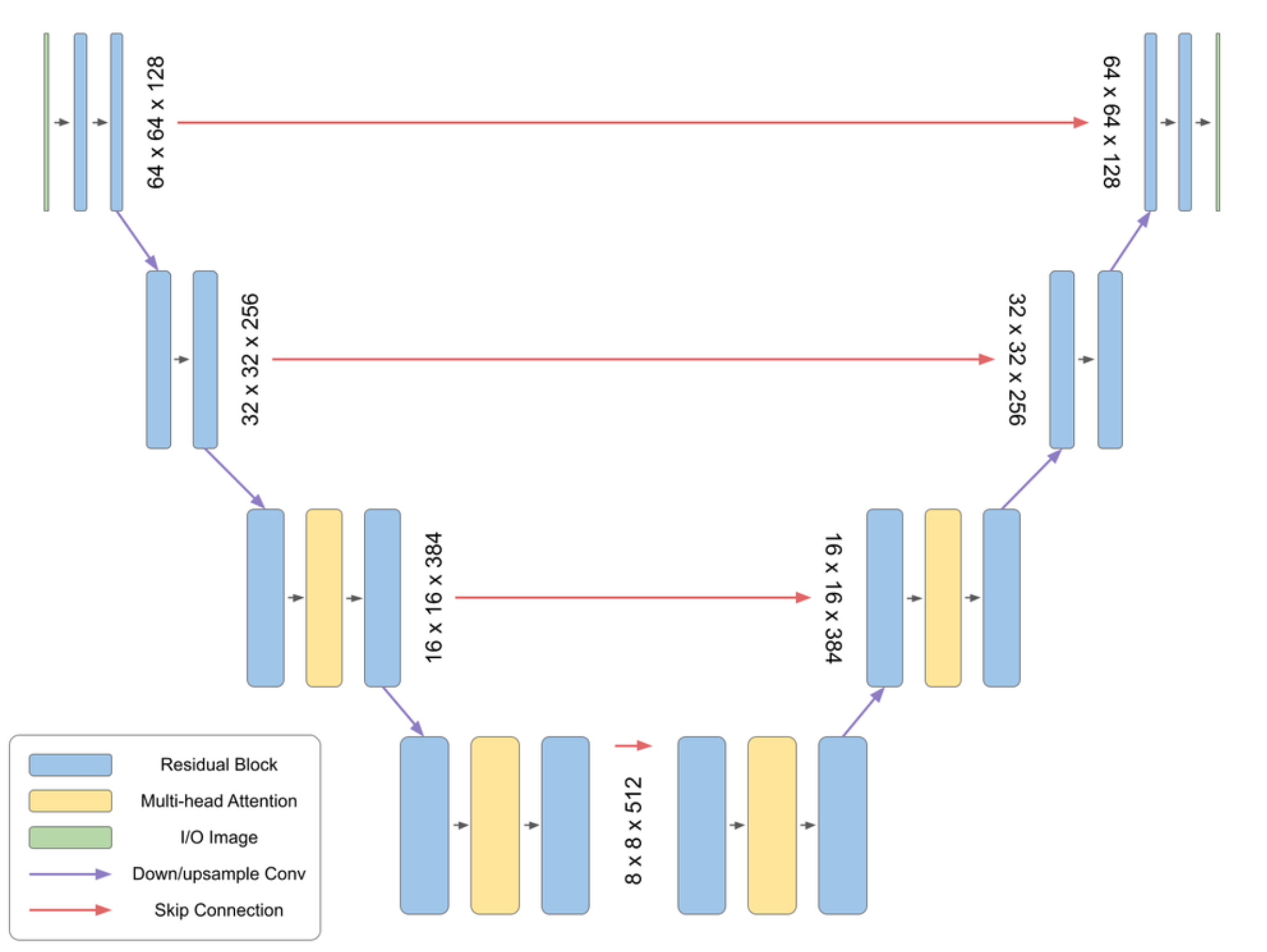
- Neural Network Design: Created a U-Net architecture that takes 16x16x3 images as input along with time steps and context vectors
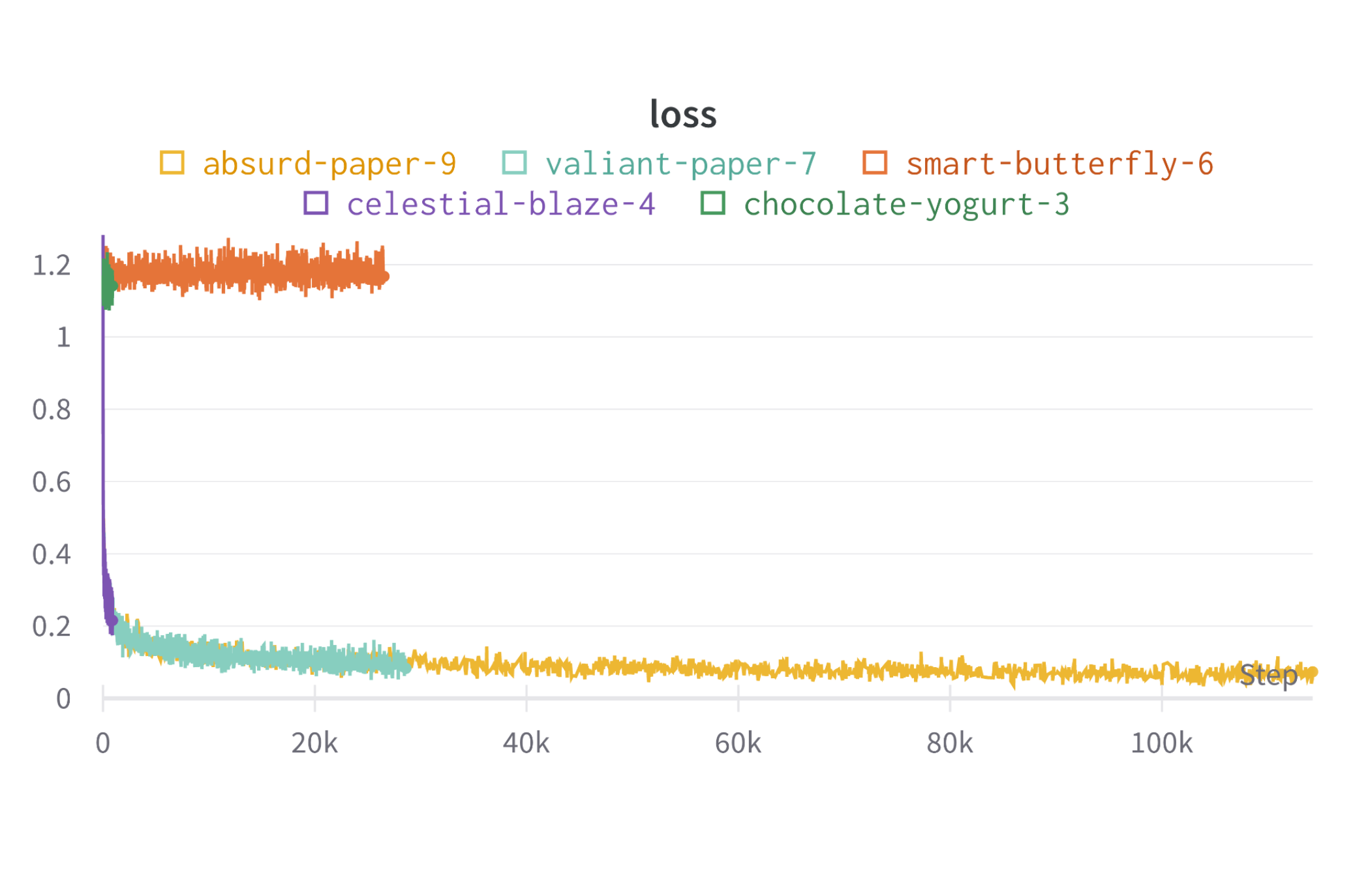
- Model Training: Trained for 100 epochs with batch size of 100, learning rate of 1e-3, using Adam optimizer and linear learning rate decay
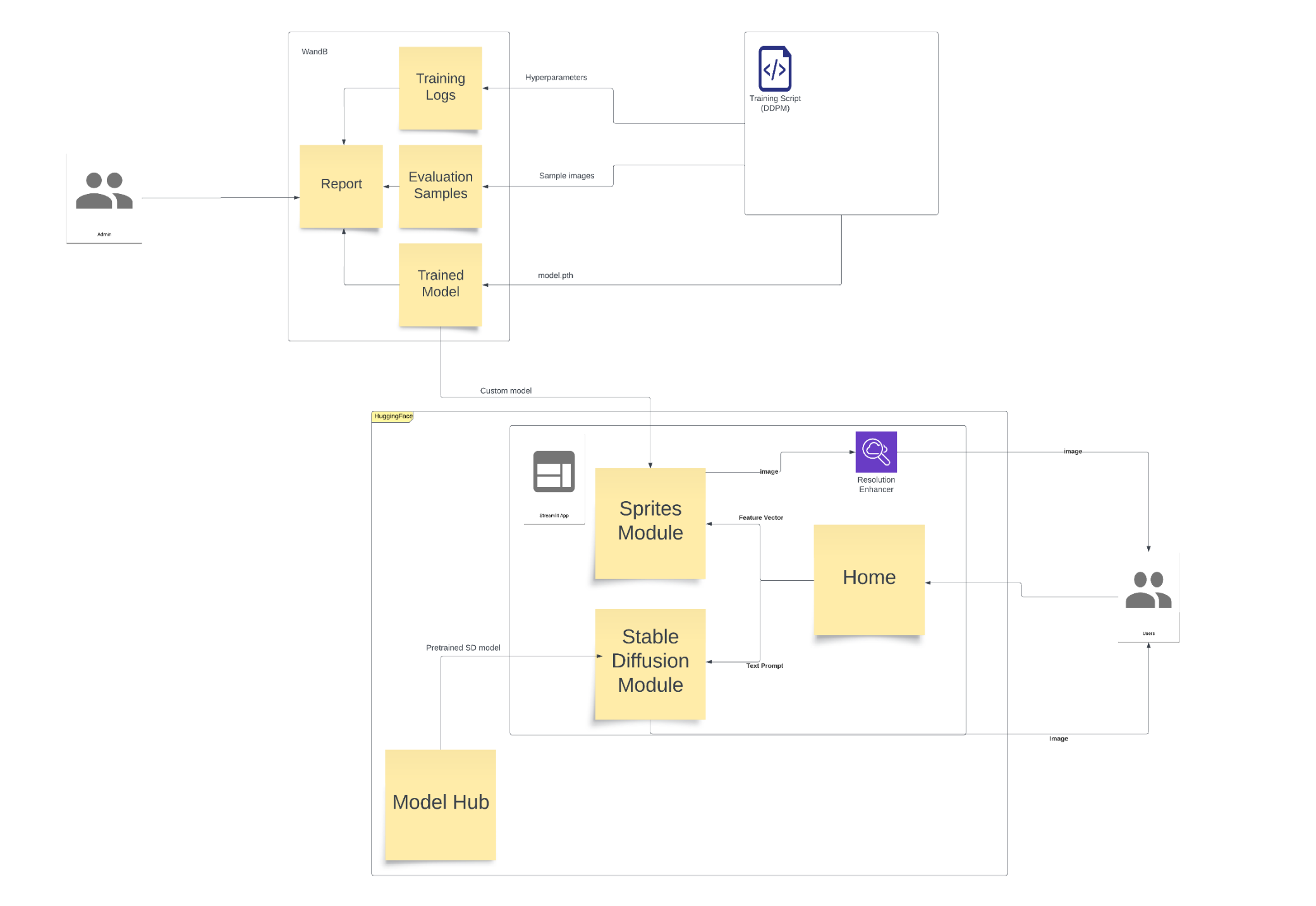
- MLOps Implementation: Used Weights and Biases to manage models, track training runs, and log hyperparameters
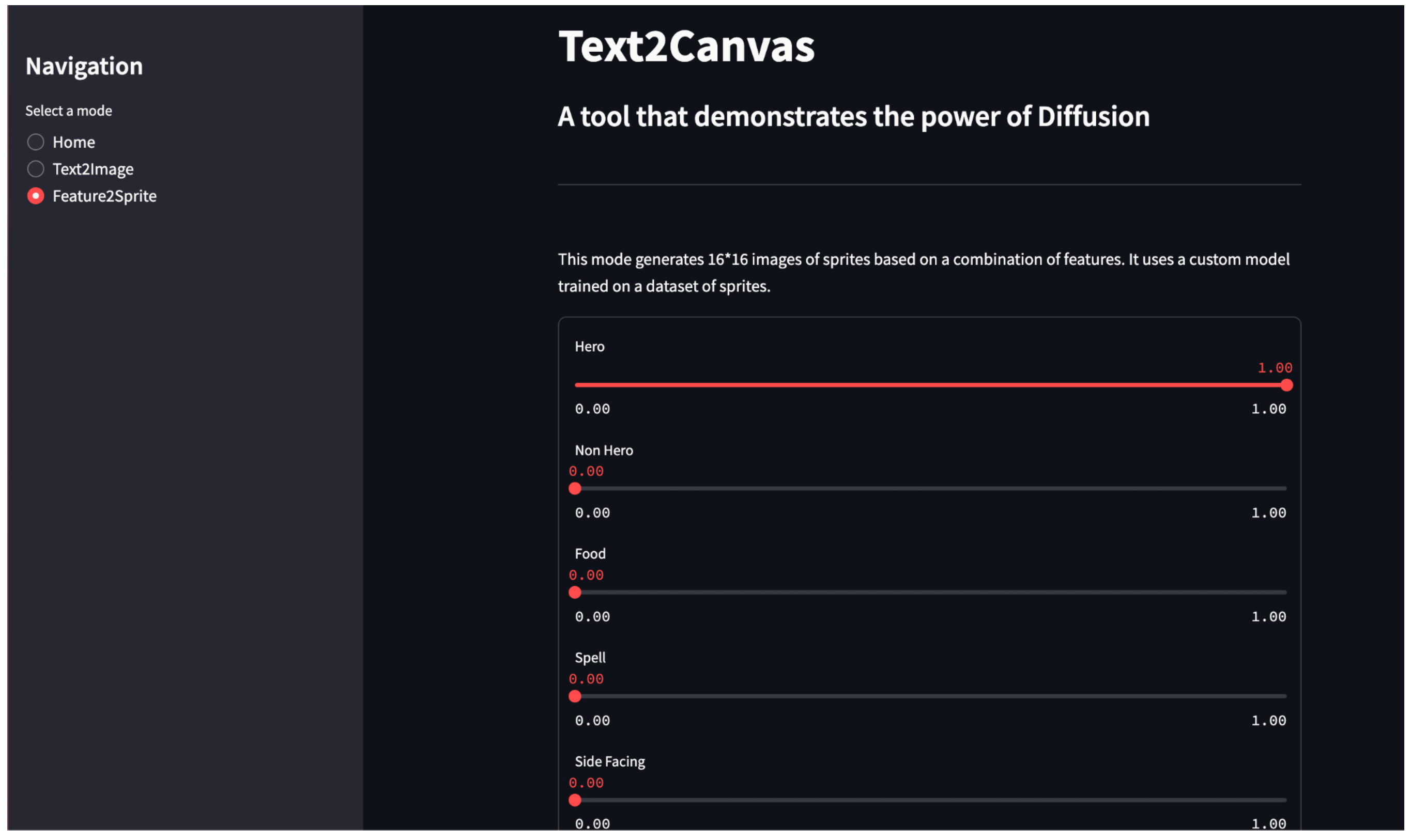
- System Architecture: Designed a two-module system offering Text-to-Image and Feature-to-Sprite generation options
- Cloud Deployment: Deployed the final system on HuggingFace Spaces for 24/7 availability
- Testing and Refinement: Evaluated model performance and refined parameters for optimal results
Tools and Technologies
The project utilized a comprehensive set of tools and technologies:
Platforms:
- HuggingFace Spaces
- Google Colab
- VS Code
- Git/GitHub
- Weights and Biases
Programming Language:
- Python
Libraries:
- PyTorch/Torch
- torchvision
- tqdm
- wandb
- matplotlib
- IPython
- torchvision
- numpy
- pathlib
- IPython.display
Model Architecture:
- U-Net diffusion model (combining U-Net with diffusion techniques)
- T5 text encoder for processing textual descriptions
- Denoising Diffusion Probabilistic Model (DDPM) algorithm
- Feature-to-sprite conversion pipeline
Advancing Creative AI through Generative Models
Text2Canvas demonstrates the practical application of generative AI in creative content production, particularly for game development and digital art creation. Despite resource limitations, we successfully developed a system that enables users to generate sprites based on feature vectors.
The project's significance lies in its approach to making generative AI more accessible and specialized. By focusing on sprite generation, we created a tool that addresses specific needs in game development and digital art creation. The implementation of diffusion models on resource-constrained platforms showcases how advanced AI can be adapted for practical use cases without requiring enterprise-level infrastructure.
Future development plans include enhancing the model with animation capabilities, expanding the training dataset for more diverse sprite generation, implementing additional style controls for more precise outputs, and improving the quality and resolution of generated images with access to better computational resources.