

Project information
- Category: Machine Learning, Computer Vision, Dimensionality Reduction, Pattern Recognition
- Project date: February, 2023
- GitHub: Kuzushiji-MNIST Classification
- Technologies: Python, scikit-learn, PCA, Kernel PCA, MDS, k-Nearest Neighbors
Introduction
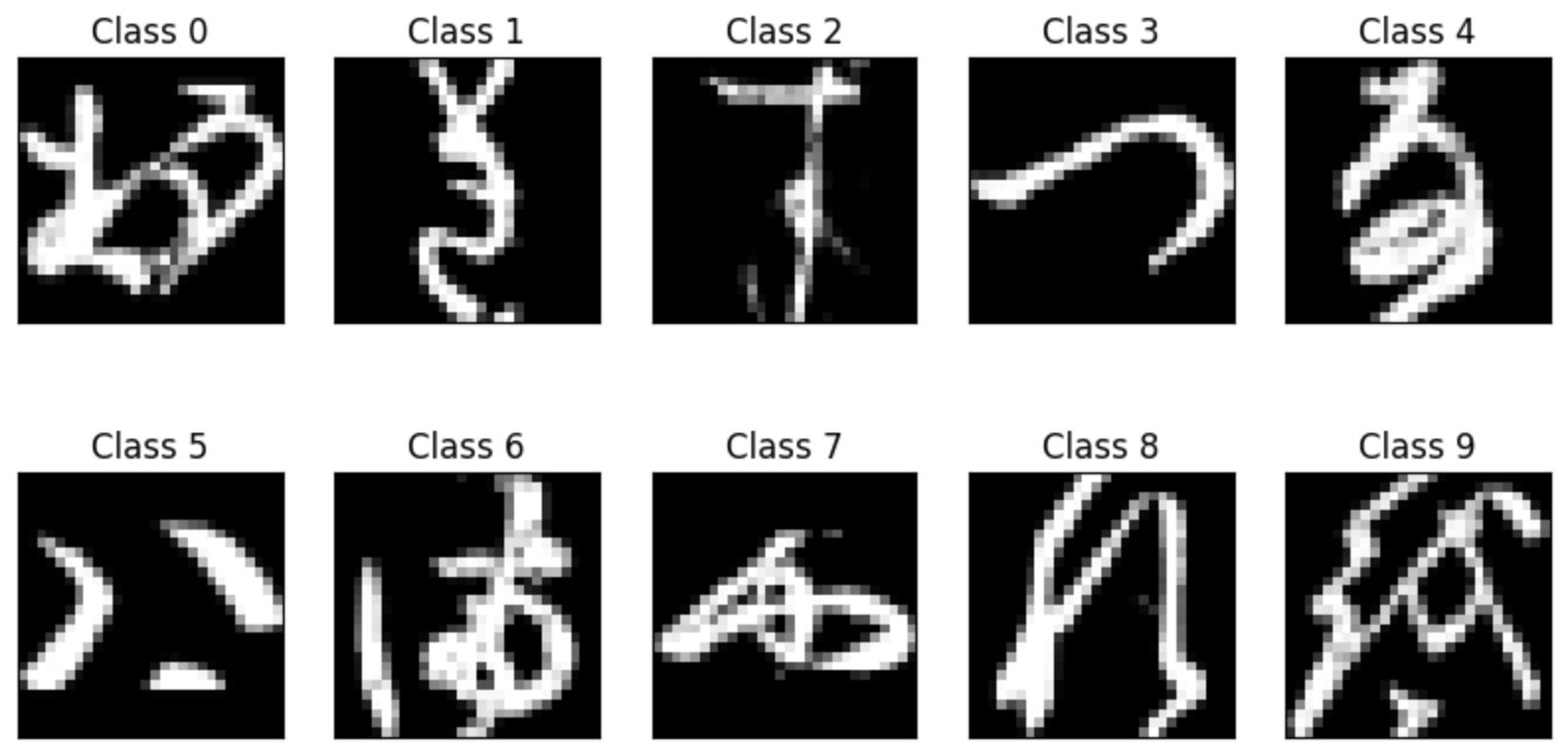
The Kuzushiji-MNIST dataset presents a fascinating challenge in the field of computer vision and pattern recognition. It consists of handwritten Japanese characters (kuzushiji) from the Edo period (1603-1868), representing a more complex classification problem than the traditional MNIST dataset of handwritten digits.
This project explores various dimensionality reduction techniques and classification methods to accurately recognize these historical Japanese characters. By comparing approaches like Principal Component Analysis (PCA), Kernel PCA, and Multidimensional Scaling (MDS), the project demonstrates how advanced dimensionality reduction can significantly improve classification accuracy on complex image datasets.
Objective
The primary objectives of this project were to:
- Implement and compare different dimensionality reduction techniques for image classification
- Determine the optimal number of training samples for efficient model training
- Evaluate the performance of various kernel functions in Kernel PCA
- Identify the most effective classification approach for the Kuzushiji-MNIST dataset
- Optimize hyperparameters to achieve maximum classification accuracy
- Demonstrate the advantages of non-linear dimensionality reduction for complex image data
- Create a comprehensive analysis pipeline for historical character recognition
Process
The development of this Kuzushiji-MNIST classification project involved several key phases:
- Data Acquisition and Exploration: Obtained the Kuzushiji-MNIST dataset and performed initial exploratory data analysis
- Data Preprocessing: Normalized and prepared the image data for dimensionality reduction
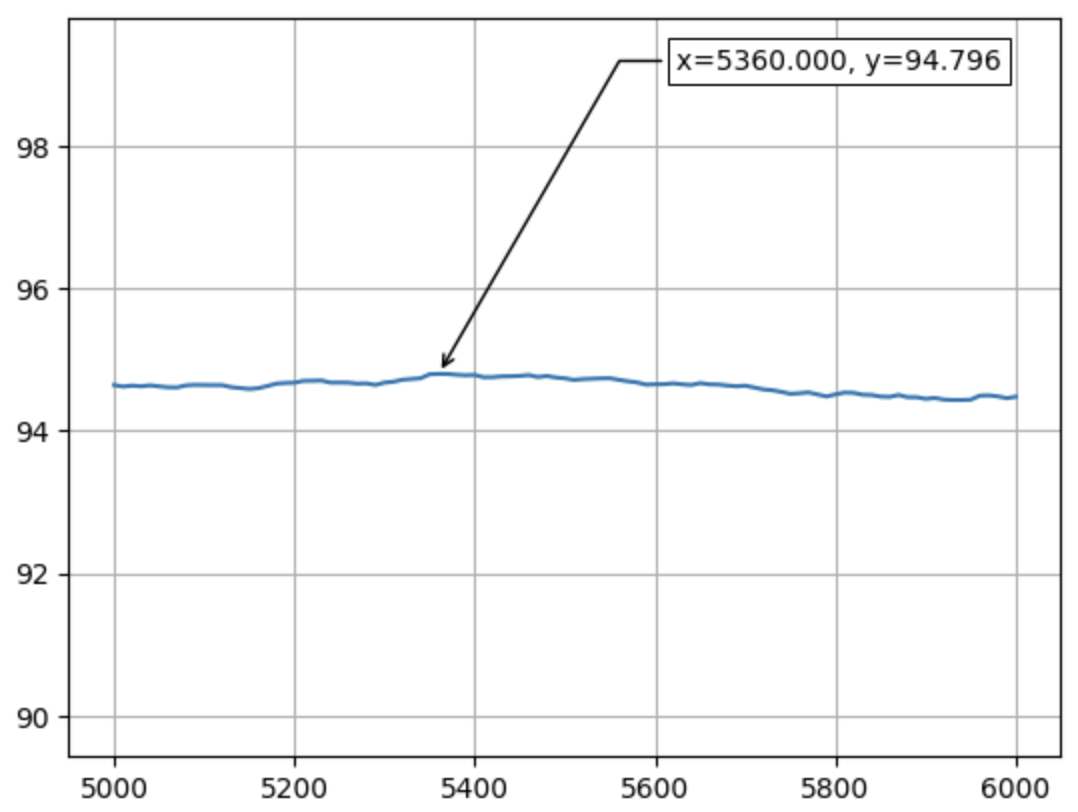
- Sample Size Optimization: Systematically tested different sample sizes (N) to determine the optimal training set size
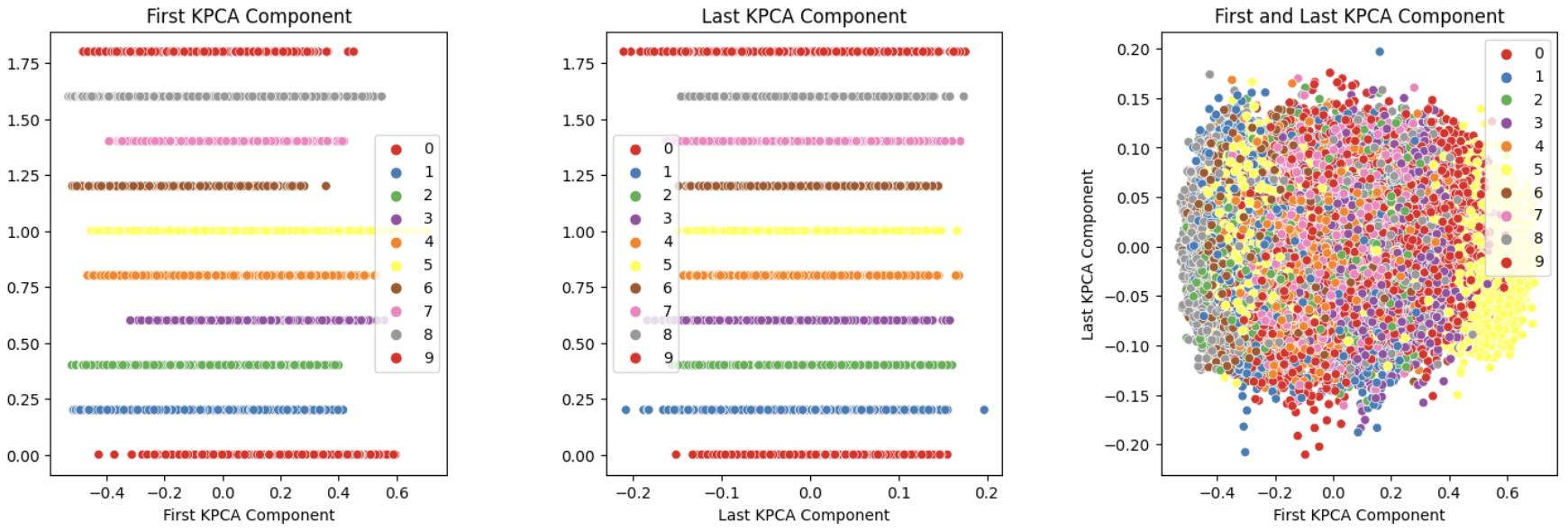
- Dimensionality Reduction Implementation: Applied PCA, Kernel PCA with various kernels, and MDS to reduce the feature space
- Classification Model Development: Implemented k-Nearest Neighbors (kNN) classifier with various configurations
- Hyperparameter Tuning: Optimized the number of components for dimensionality reduction and k value for kNN
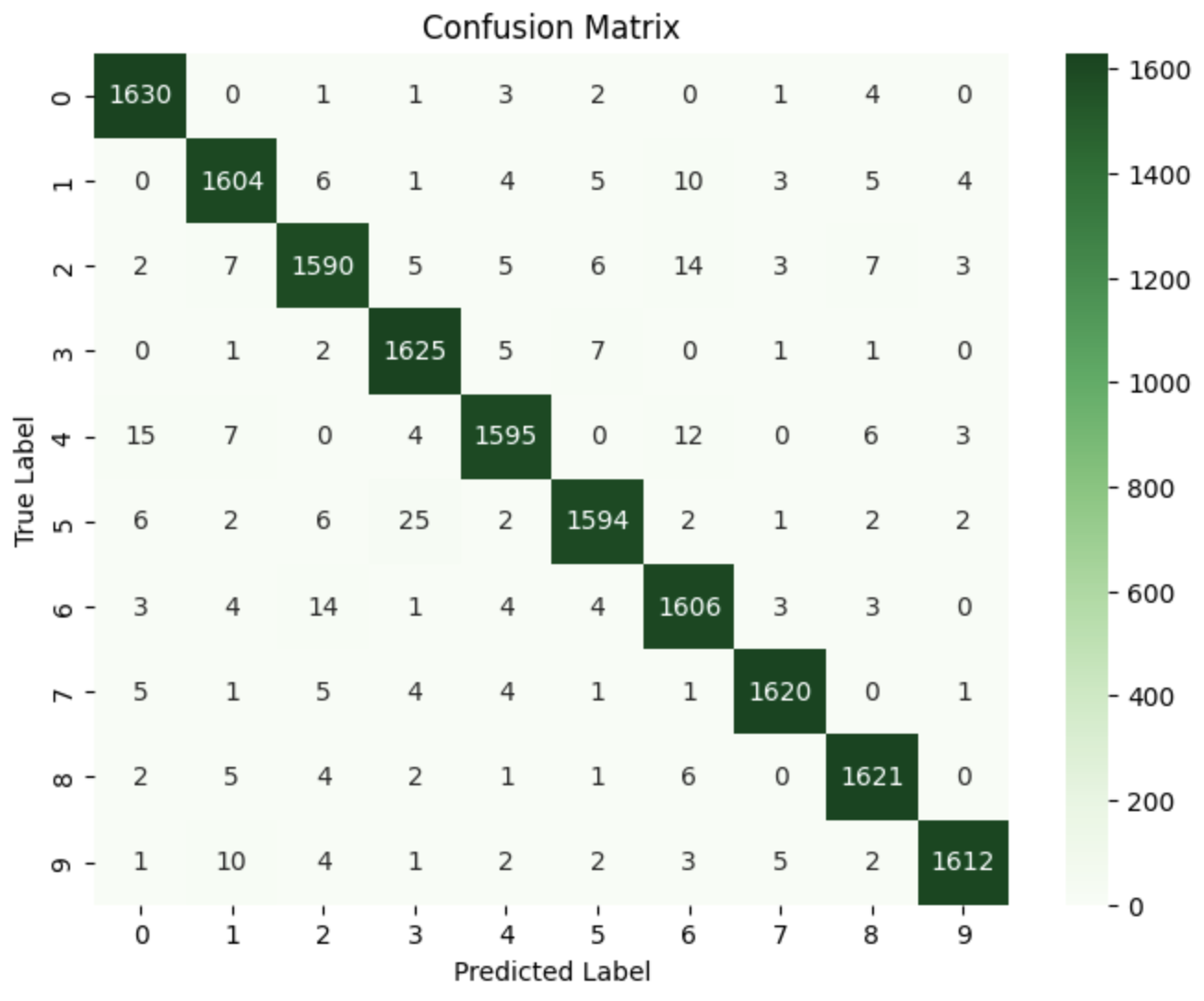
- Performance Evaluation: Generated confusion matrices and calculated accuracy metrics to assess model performance
- Comparative Analysis: Compared the performance of different dimensionality reduction techniques
- Results Visualization: Created visualizations to illustrate the effectiveness of different approaches
- Final Model Selection: Determined the optimal configuration based on comprehensive performance analysis
Results & Findings
The project yielded several significant findings:
Sample Size Optimization:
- Initial broad range testing (1000-6000, step 1000)
- Narrowed to 4000-6000 (step 100)
- Further refined to 5000-6000 (step 10)
- Final refinement to 5300-5400 (step 1)
- Optimal sample size identified: N = 5358 with accuracy of 94.81%
Dimensionality Reduction Comparison:
- Standard PCA showed reasonable performance but was limited in capturing non-linear relationships
- Kernel PCA with cosine kernel significantly outperformed standard PCA
- The optimal configuration used 72 components for Kernel PCA
- MDS showed competitive results but was computationally more expensive
Classification Performance:
- The k-Nearest Neighbors algorithm with k=3 provided the best classification results
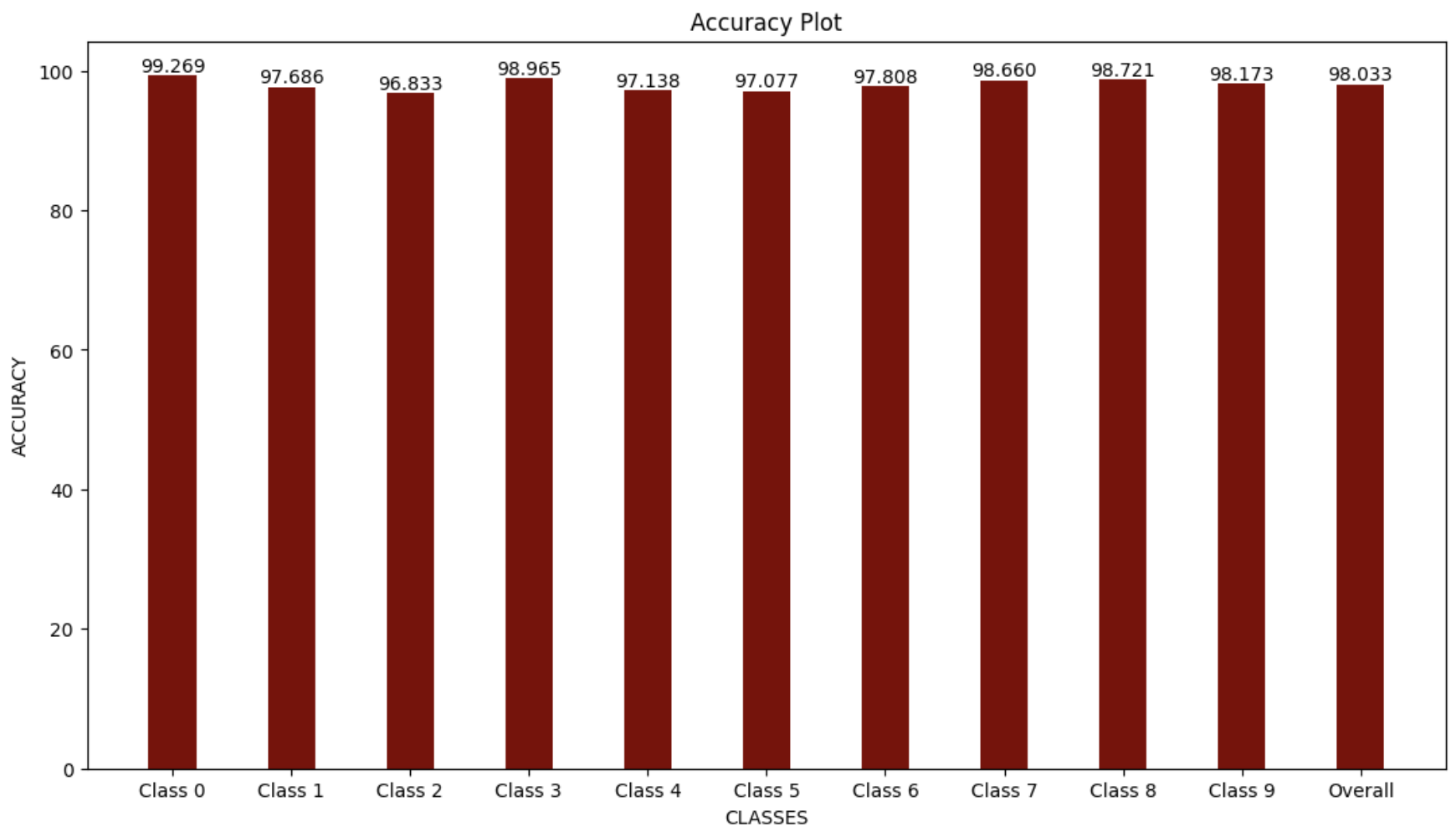
- The combination of Kernel PCA (cosine kernel, 72 components) and kNN (k=3) achieved 98.03% accuracy
- This represents a significant improvement over baseline methods
- The confusion matrix showed strong performance across all character classes
Tools and Technologies
This project leveraged a comprehensive set of tools and technologies:
Platforms:
- Google Colab
- GitHub
- VS Code
Programming Language:
- Python 3.x
Libraries:
- NumPy
- pandas
- scikit-learn
- Matplotlib
- Seaborn
- Jupyter Notebook
Techniques and Algorithms:
- Principal Component Analysis (PCA)
- Kernel Principal Component Analysis (Kernel PCA)
- Multidimensional Scaling (MDS)
- k-Nearest Neighbors (kNN) Classification
- Cross-validation
- Confusion Matrix Analysis
- Hyperparameter Optimization
Advanced Results with Dimensionality Reduction and Simple ML Model
This project demonstrated the significant advantage of non-linear dimensionality reduction techniques for complex image classification tasks. The Kuzushiji-MNIST dataset, with its intricate historical Japanese characters, presented a challenging problem that standard approaches struggled to solve efficiently.
The systematic optimization of sample size, dimensionality reduction technique, and classification parameters yielded an impressive 98.03% accuracy on the test set. Specifically, the combination of Kernel PCA with a cosine kernel (72 components) and a k-Nearest Neighbors classifier (k=3) proved most effective.
This work highlights the importance of selecting appropriate dimensionality reduction techniques based on the nature of the data. For complex image datasets like Kuzushiji-MNIST, techniques that can capture non-linear relationships between features (such as Kernel PCA) significantly outperform linear methods.
The methodical approach to optimization demonstrated in this project can serve as a template for tackling similar image classification challenges, particularly those involving historical or cultural artifacts where pattern recognition can aid in preservation and study.