



Project information
- Category: Machine Learning, Computer Vision, Image Classification, Feature Extraction
- Project date: June, 2023
- GitHub: CIFAR-10
Introduction
This project focuses on image classification and feature extraction techniques applied to the CIFAR-10 dataset using PyTorch. The CIFAR-10 dataset is a benchmark in computer vision, consisting of 60,000 32x32 color images across 10 different classes (airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck).
The project demonstrates how convolutional neural networks (CNNs) can be leveraged for both classification tasks and feature extraction. Beyond simply classifying images, the feature extraction component reveals what patterns and representations the network learns at different layers, providing insights into how deep learning models "perceive" visual information.
Objective
The primary objectives of this project were to:
- Develop a convolutional neural network architecture for effective image classification on the CIFAR-10 dataset
- Extract meaningful features from intermediate layers of the network to understand learned representations
- Visualize these features using dimensionality reduction techniques to gain insights into the model's decision-making
- Implement data augmentation strategies to improve model generalization
- Analyze per-class performance to identify strengths and weaknesses of the model
- Compare different optimization techniques and hyperparameter settings for optimal performance
- Create a reusable framework for both classification and feature extraction tasks
- Demonstrate the value of feature extraction in understanding deep learning models
Process
The development of this project involved several key phases:
- Dataset Preparation: Loaded the CIFAR-10 dataset using PyTorch's torchvision library and applied normalization transforms to prepare images for training
- Data Visualization: Created functions to display and analyze sample images from the dataset to understand the classification challenge
- CNN Architecture Design: Developed a convolutional neural network with multiple convolutional layers, max pooling layers, and fully connected layers for classification
- Training Pipeline Setup: Implemented a training loop with cross-entropy loss and SGD optimizer with momentum
- Model Training: Trained the model over multiple epochs with batch processing, monitoring the loss reduction over time
- Model Evaluation: Assessed the model's performance on the test set and calculated overall accuracy metrics
- Per-Class Analysis: Analyzed classification accuracy for each individual class to identify strengths and weaknesses
- Feature Map Extraction: Extracted activations from intermediate layers of the network to visualize learned features
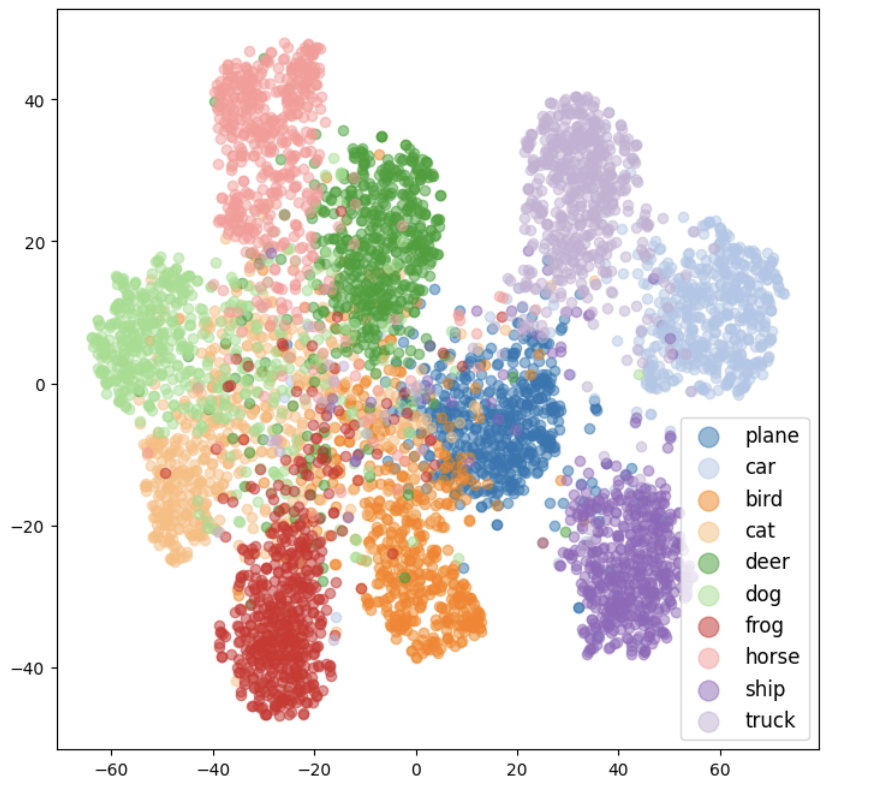
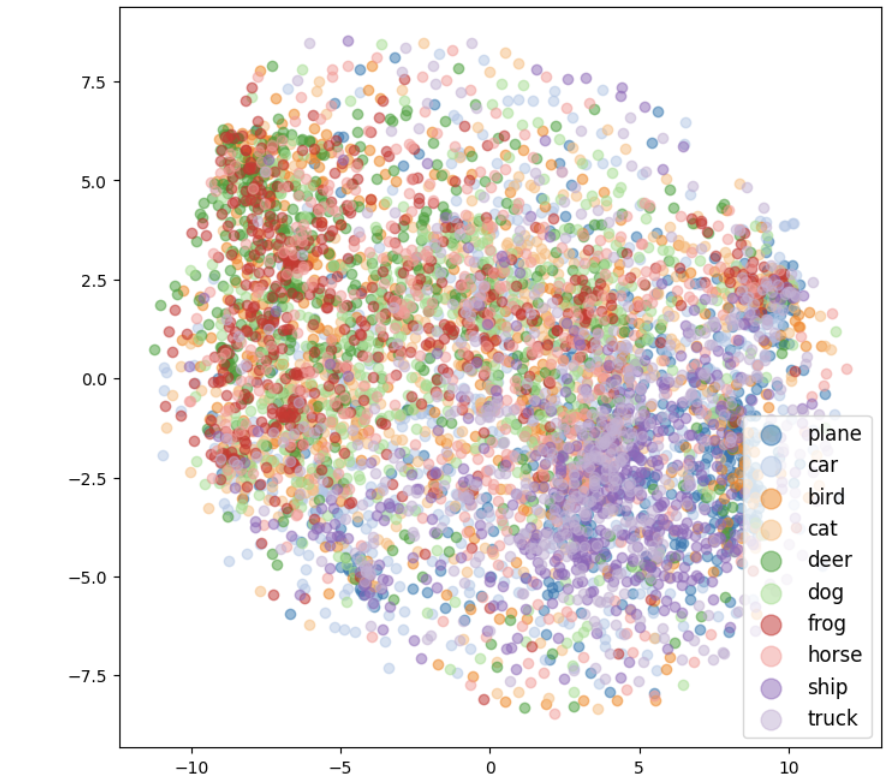
- Feature Visualization: Applied dimensionality reduction techniques (PCA, t-SNE) to visualize high-dimensional feature spaces
- Activation Maximization: Implemented techniques to find input patterns that maximize specific neuron activations
- Filter Visualization: Visualized convolutional filters to understand what patterns each filter is detecting
- Class Activation Mapping: Implemented CAM techniques to highlight image regions most influential for classification
- Hyperparameter Tuning: Experimented with different learning rates, batch sizes, and model architectures
- Performance Optimization: Refined the model architecture and training process to improve accuracy
- Comparative Analysis: Evaluated different feature extraction approaches to identify the most insightful methods
Tools and Technologies
This project leveraged a comprehensive set of tools and technologies:
Platforms:
- Google Colab (primary development environment)
- Jupyter Notebook
- GitHub (version control and project hosting)
Programming Language:
- Python 3.x
Libraries:
- PyTorch
- torchvision
- NumPy
- Matplotlib
- scikit-learn
- Pandas
- PIL/Pillow
Techniques and Algorithms:
- Convolutional Neural Networks (CNNs)
- Principal Component Analysis (PCA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Class Activation Mapping (CAM)
- Transfer Learning
- Gradient-Based Optimization
- Data Augmentation
- Feature Visualization
Understanding Deep Learning Through Feature Extraction
This project demonstrates the power of feature extraction in demystifying convolutional neural networks. By visualizing the features learned at different layers, we gain valuable insights into how CNNs process and interpret visual information.
The classification results showed varying accuracy across different classes, with the model achieving approximately 54% overall accuracy on the test set. Some classes like automobiles and trucks were more consistently recognized (70-75% accuracy), while others like cats and deer proved more challenging (24-30% accuracy). These performance differences highlight the varying complexity of visual patterns across different object categories.
Through feature extraction and visualization, we observed how the network progressively builds more complex representations: early layers detect simple edges and textures, middle layers identify more structured patterns and shapes, while deeper layers capture high-level object parts. This hierarchical representation learning is fundamental to the success of deep learning in computer vision tasks.
The project serves as both a practical implementation of image classification and a window into the inner workings of neural networks, demonstrating how feature extraction can bridge the gap between black-box models and interpretable AI.